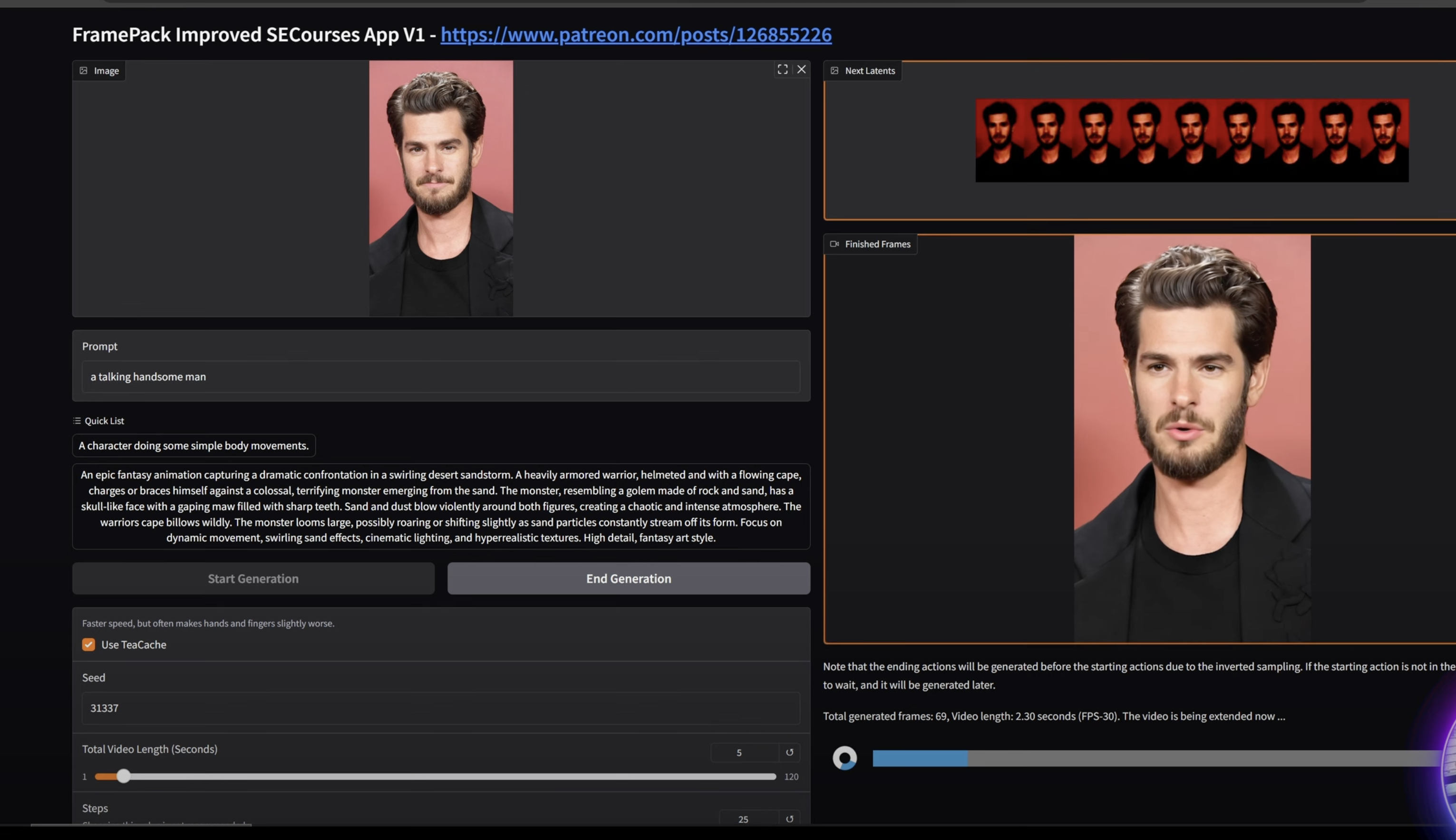
FramePack introduces a groundbreaking approach to video frame processing, enabling users to diffuse thousands of frames at full 30fps with 13B models using just 6GB of laptop GPU memory. This exceptional efficiency stems from our innovative frame context packing methodology that optimizes GPU resource allocation based on frame importance.
Unlike traditional video generation models that require substantial computational resources, FramePack intelligently compresses input frames with varying patchifying kernels, giving more GPU resources to critical frames. This allows professionals and hobbyists alike to work with high-quality video generation on consumer-grade hardware, democratizing access to advanced AI video tools.
One of FramePack's most remarkable achievements is its constant O(1) computation complexity for streaming operations. Traditional next-frame prediction models suffer from increasing computational demands as videos lengthen, but FramePack maintains consistent performance regardless of video duration.
This revolutionary approach means that FramePack can generate videos of arbitrary length without performance degradation. The system achieves this through our patent-pending frame scheduling mechanism that maintains optimal memory usage patterns throughout the generation process. Video professionals using FramePack benefit from predictable processing times and consistent quality, even when working with extended sequences that would overwhelm conventional systems.

FramePack solves one of the most persistent challenges in video generation: quality degradation over time, commonly known as drifting or error accumulation. Our proprietary anti-drifting sampling technique breaks causality constraints by implementing bi-directional sampling methodologies that maintain consistent quality from the first frame to the last.
While conventional models rapidly deteriorate after 5-10 frames of generation, FramePack maintains remarkable consistency even when generating hundreds of frames. This breakthrough was achieved through extensive research into frame coherence and our innovative inverted anti-drifting sampling, which constantly references initial frames as approximation targets. The result is unprecedented stability in long-form video generation, opening new possibilities for content creators who need extended, high-quality outputs from their FramePack AI system.
FramePack offers unparalleled versatility through its adaptive frame scheduling system. Users can customize how compression and importance are distributed across frames, allowing optimization for specific use cases from image-to-video generation to video editing and enhancement.
With FramePack's intuitive scheduling interface, users can prioritize starting frames for image-to-video workflows, distribute importance evenly for consistent quality, or focus computational resources on complex scenes that require additional detail. This flexibility makes FramePack suitable for filmmakers, video editors, content creators, and researchers across diverse projects. The FramePack AI framework adapts to your specific needs rather than forcing your workflow to adapt to its limitations, representing a fundamental shift in how professionals interact with video generation technology.

FramePack is a revolutionary next-frame prediction model designed specifically for efficient and high-quality video generation. Developed by researchers at Stanford University, FramePack represents a paradigm shift in how video diffusion models process and manage input frame contexts, allowing for unprecedented efficiency and quality in generating video content.
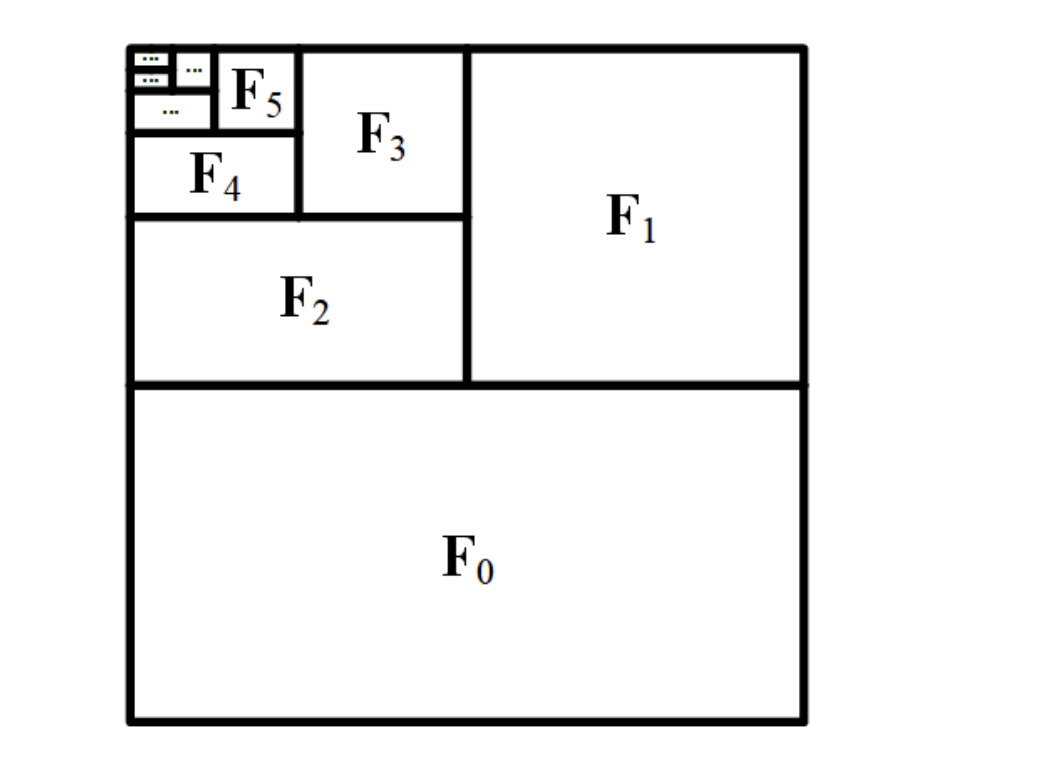
At its heart, FramePack introduces an innovative approach to encoding input frames in GPU memory layouts. Traditional video generation models struggle with lengthy sequences due to computational and memory constraints. FramePack overcomes these limitations through intelligent frame context packing, where each frame is encoded with different patchifying kernels based on its importance to the prediction target.
This unique approach allows FramePack to diffuse thousands of frames at full 30fps using 13B models on laptops with just 6GB of GPU memory—a feat previously unimaginable with conventional techniques. The system maintains O(1) computation complexity for streaming, meaning the performance remains constant regardless of video length, eliminating the performance degradation typically associated with longer sequences.
Unlike traditional video diffusion models that require substantial computational resources and often produce degrading results over time, FramePack offers several distinctive advantages:
The result is a system that feels more like image diffusion in its simplicity and accessibility, while delivering the complex capabilities of video diffusion without the typical hardware constraints or quality compromises.
Implementing FramePack in your video generation workflow is straightforward. The system is designed with accessibility in mind, allowing both professionals and enthusiasts to harness its power without extensive technical knowledge. Here's how to begin:
FramePack's intuitive interface makes it accessible even for those new to video generation technologies, while still offering advanced options for experienced users who want to fine-tune every aspect of the generation process.
One of FramePack's most powerful features is its flexible scheduling system, which allows users to customize how computational resources are allocated across frames. Different scheduling patterns serve different creative and technical needs:
The default scheduling pattern allocates more resources to frames that are temporally closer to the prediction target. This works well for most video generation tasks where recent frames have more influence on the next frame.
When generating videos from a single image (image-to-video), inverted scheduling allocates more importance to the starting frame, ensuring that the generated video maintains fidelity to the original image throughout the sequence.
For scenarios where all context frames are equally important, uniform scheduling distributes computational resources evenly, ideal for maintaining consistent quality across scenes with complex motion or detailed textures.
FramePack's scheduling flexibility allows creative professionals to tailor the generation process to their specific needs, balancing quality, speed, and resource constraints according to project requirements.
FramePack offers multiple sampling approaches to address the common problem of drifting (quality degradation over time):
By breaking the constraints of causal generation, FramePack's bi-directional sampling techniques deliver unprecedented stability in long-form video generation, opening new creative possibilities for content creators.
FramePack represents a significant step toward democratizing advanced video generation technology. By dramatically reducing hardware requirements, FramePack makes professional-quality video generation accessible to creators who don't have access to expensive computational resources. This democratization has profound implications for independent filmmakers, content creators, researchers, and hobbyists who previously couldn't access such advanced tools.
With FramePack, a standard laptop with a modest GPU can now perform tasks that previously required specialized hardware. This accessibility expands the creative possibilities for a wider range of users and applications, from educational content to independent films.
Perhaps FramePack's most revolutionary aspect is its ability to maintain consistent quality across extremely long video sequences. While traditional models typically degrade after generating just 5-10 frames, FramePack can maintain quality integrity across hundreds or even thousands of frames.
This capability opens new possibilities for long-form content generation, from cinematic sequences to educational videos, where maintaining visual consistency throughout the duration is critical. Content creators can now think beyond short clips and explore extended narratives with confidence.
For researchers and developers, FramePack offers an efficient platform for experimentation and innovation in video generation. The ability to finetune 13B video models at batch size 64 on a single node makes it feasible for academic labs and individual researchers to conduct experiments that were previously only possible with industrial-scale resources.
This accessibility accelerates the pace of innovation in the field, potentially leading to new applications and improvements in video generation technology. FramePack thus serves not only as a tool for content creation but also as a foundation for further advancement in AI-powered video technologies.
FramePack is designed to run efficiently on consumer-grade hardware. At minimum, you'll need a laptop or desktop with a 6GB GPU for basic functionality. For optimal performance, an RTX 4090 or equivalent can generate frames at speeds of 1.5-2.5 seconds per frame. Unlike many video generation systems, FramePack doesn't require specialized hardware like multiple A100 GPUs, making it accessible to a much wider audience.
Yes, FramePack supports multiple resolutions for video generation. The system is flexible and can be configured to output videos at various resolutions depending on your needs and available computational resources. Higher resolutions will require more GPU memory and processing time, but FramePack's efficient architecture still makes this feasible on consumer hardware.
FramePack distinguishes itself from other video generation models through its exceptional efficiency and consistent quality over long sequences. While many models require significant computational resources and suffer from quality degradation over time (drifting), FramePack maintains consistent quality across hundreds of frames while running on modest hardware. Its O(1) computation complexity for streaming also means performance doesn't degrade with longer videos, unlike most other models.
While FramePack is significantly more efficient than traditional video generation models, it's not yet designed for real-time applications at full quality. However, with teacache optimization, it can achieve generation speeds of approximately 1.5 seconds per frame on high-end consumer GPUs like the RTX 4090. This makes it suitable for near-real-time applications where some latency is acceptable.
Absolutely. FramePack is designed with interoperability in mind and can be integrated into broader AI workflows and pipelines. It works well alongside other tools for image generation, video editing, and post-processing. The API is designed to be accessible and adaptable, allowing developers to incorporate FramePack into existing systems or build new applications around its capabilities.
FramePack excels at generating consistent, high-quality video sequences from either initial images (image-to-video) or existing video contexts (video-to-video). It's particularly well-suited for applications requiring long-form content with consistent visual quality, such as narrative sequences, educational content, visual effects, and creative projects. The flexibility of its scheduling system also makes it adaptable to various content types and creative needs.